IPFS stands for InterPlanetary File System and it is a different way to access files on the Internet than the standard HTTP request that we all currently use.
What’s interesting about IPFS is that it uses hashes to store data and then it links directly to that data. In the current system with HTTP, resources are put in link structure on websites and servers.
For example: https://skypointwebdesignbillingsmontana.com/what-is-ipfs/ the root URL is https://skypointwebdesignbillingsmontana.com/ and the article is located at what-is-ipfs/
This link structure is easy for humans to read, but not as easy for machines to read. What is special about IPFS is that it is way quicker for machines to read and return the data when requested.
I first learned about this technology in a post from my LinkedIn connection Keir Finlow-Bates, who put out this video today:

Currently there is no active integration of this system in our common browsers such as Chrome, Firefox or Safari. However, a new browser called Brave does have active IPFS standard included.
This allows users of Brave to search the IPFS and the HTTP system at the same time to locate both files and websites in the quickest way possible, respectively.
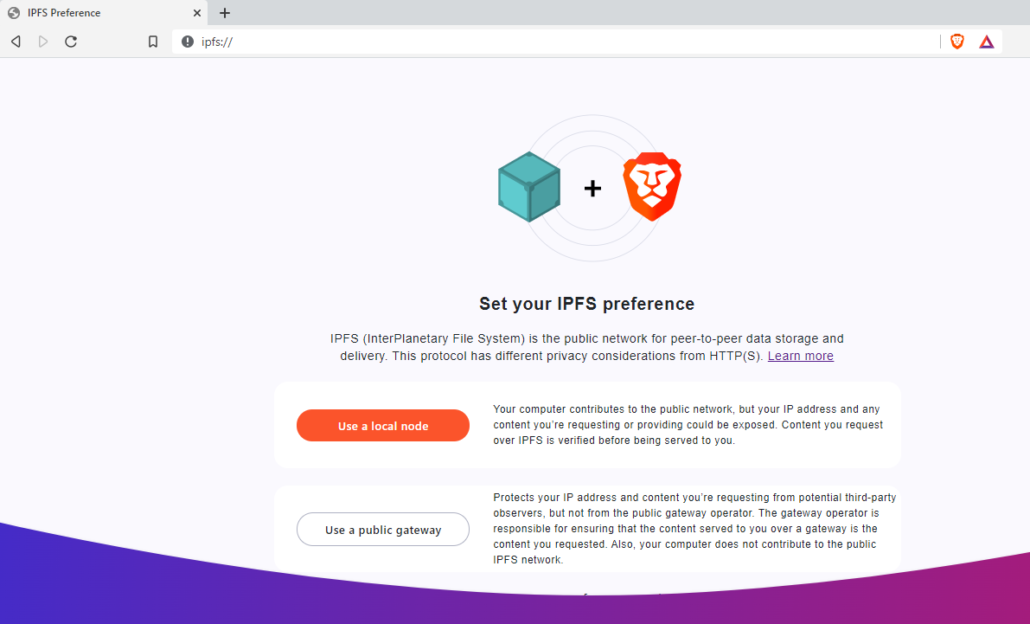
In the future, we may be using a IPFS for all documents located on the web, as it will require much less processing power to access and retrieve the documents when requested.
One thought that I have as a marketer and SEO is how will search engines find these files with just a hash?
I assume they will probably come up with some type of metadata attachment to the documents, however this is yet to be decided.
What are your thoughts about this new standard and do you think it will catch on? Sound off in the comments!






Customer Support
____________________________________________ Looking for SEO in Billings, MT? Ask us why we are the secret ingredient to your business ranking #1
SEARCH OPTIMIZATION




____________________________________________ Looking for SEO in Billings, MT? Ask us why we are the secret ingredient to your business ranking #1
SEARCH OPTIMIZATION

Leave a Reply
Want to join the discussion?Feel free to contribute!